Crawling is like an adventure for search engines. They dispatch a squad of robots, often called crawlers or spiders, to hunt down fresh and recently changed content. The search engine crawler it content can take many forms, from webpages and images to videos and PDFs. Regardless of the type, search engines find this content by following links.
Search engine crawlers, also known as web spiders, web crawlers, or bots, are automated programs that browse the internet, visiting websites, and collecting data to index and rank content in search engine results. They are the workhorses behind search engines like Google, Bing, and Yahoo.
These crawlers systematically navigate the vast expanse of the internet, following links from one web page to another, and analyzing the content of each page they encounter.
Some working methods of SE Crawler -
1.)Seed URLs:
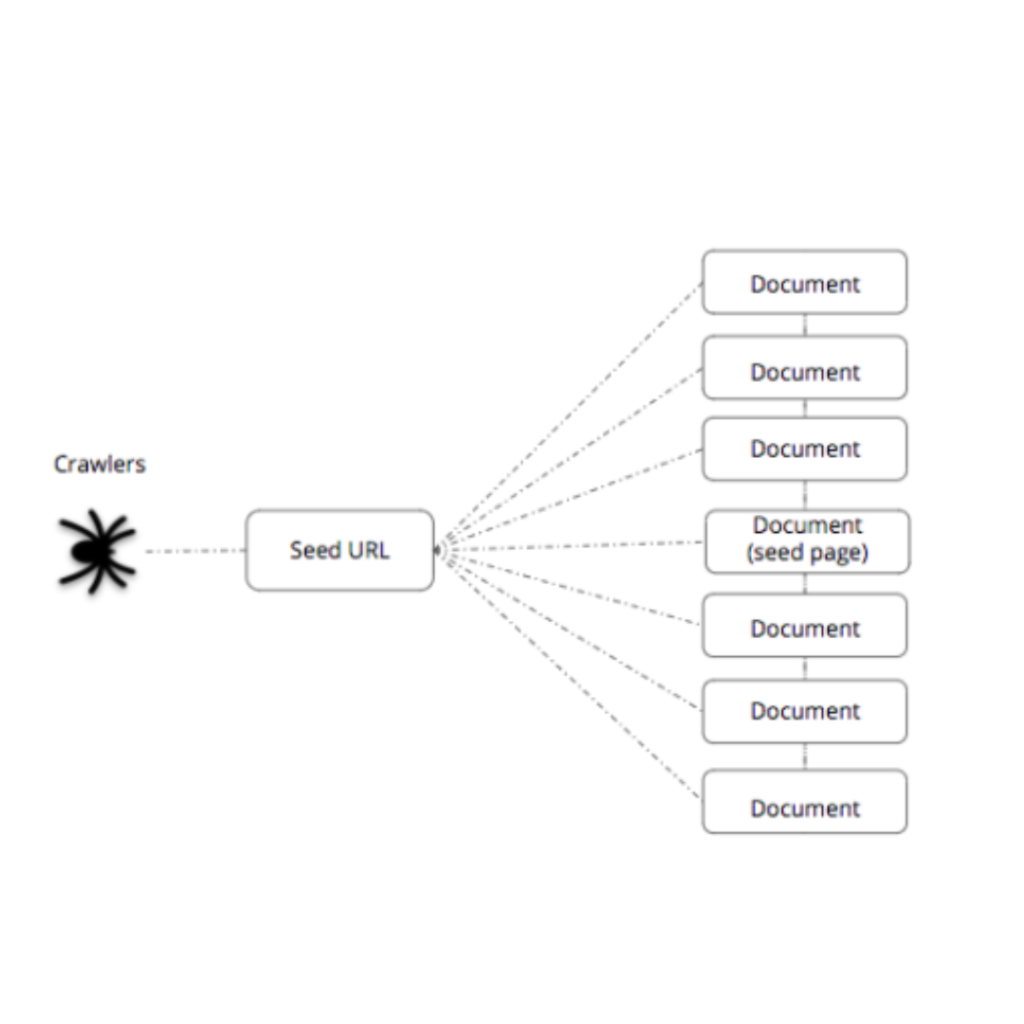
At the beginning of their journey, search engine crawlers are given a starting point—a list of seed URLs. These URLs often include well-known websites and pages that have been previously indexed. From these starting points, the crawlers set off on their mission, exploring the internet one page at a time.
2.)Fetching Web Pages:
The first task of a crawler is to request web pages from the servers that host them. To do this, the crawler sends out HTTP requests to these web servers. In response, the servers provide the necessary elements, such as HTML, CSS, images, and other resources, required to display the web page.
3.)Parsing HTML:
With the web page’s raw HTML code in hand, the crawler takes the next step. It carefully examines the HTML to extract valuable information. This includes the text content on the page, links leading to other pages, metadata (information about the page), and much more. Think of it as the crawler reading the page’s “recipe” to understand what’s inside.
4.)Following Links:
One of the key ways crawlers discover new pages is by following links within the pages they visit. As they analyze the content of a page, they keep an eye out for hyperlinks. When they find one, they venture down that link, effectively moving from one web page to another. This process creates a vast network of interconnected content, like an intricate web.
5.)Indexing :
After collecting all this valuable information from a web page, the crawler organizes it. Think of this step as filing away the collected data in a massive library. The information is added to the search engine’s database, which acts like a catalog. This database is what makes it possible for search engines to retrieve relevant results when you enter a search query. It helps the search engine understand what each web page is about, making it easier to match it to your search.
In the digital world, websites are constantly changing with content being updated, restored, and new pages being added. To ensure they remain up-to-date, search engine crawlers frequently review web pages in a process known as recrawling. This involves going back to pages they’ve previously visited to check for changes and updates. The frequency of recrawling can vary depending on the site’s administration, how often it updates its content, and other factors.



Leave A Comment